Contents
Introduction
Artificial Intelligence is evolving rapidly, but one major limitation of Large Language Models (LLMs) is their inability to access real-time or private data. This is where Retrieval-Augmented Generation (RAG) comes into play.
RAG is transforming how AI applications work by combining LLMs with external knowledge sources, enabling more accurate, relevant, and up-to-date responses.
In this guide, we’ll break down RAG from scratch – covering concepts, architecture, and implementation.
What is RAG?
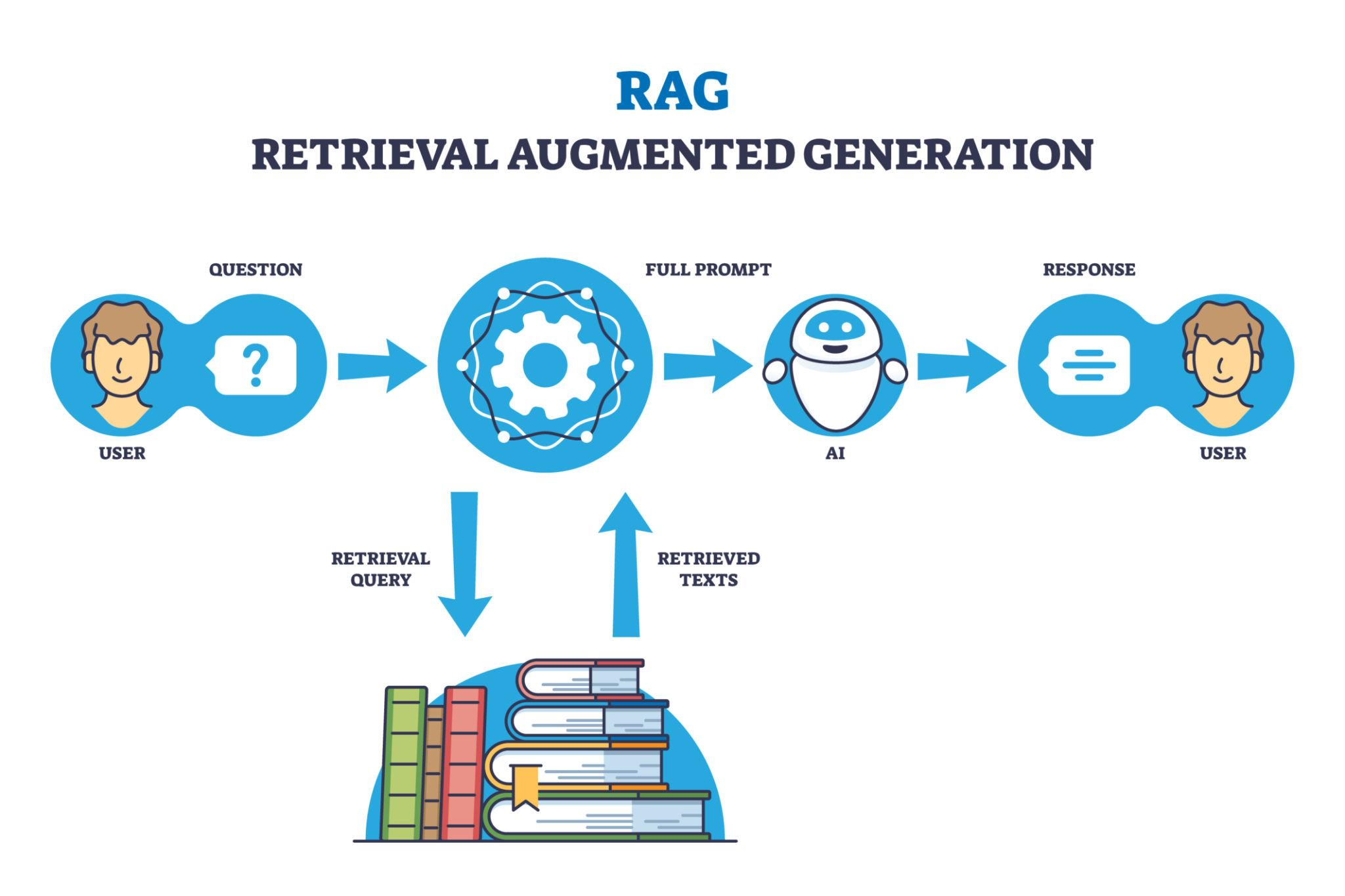
Retrieval-Augmented Generation (RAG) is a technique that enhances LLM outputs by retrieving relevant data from external sources before generating a response.
As explained in the training material :
- RAG improves LLM accuracy by referencing external knowledge bases
- It eliminates the need for expensive fine-tuning
- It enables domain-specific and real-time responses
In simple terms:
RAG = LLM + External Knowledge + Smart Retrieval
Why Do We Need RAG?
Traditional LLM-based applications have key limitations:
1. Hallucination Problem
- LLMs generate answers even when they don’t know the truth
- Leads to incorrect or misleading responses
2. No Real-Time Knowledge
- Models are trained on past data
- They cannot access recent events or updates
3. No Access to Private Data
- Company documents, policies, and internal data are not included
- Fine-tuning is expensive and impractical
RAG solves all these problems efficiently.
How RAG Works (Architecture Explained)
RAG consists of two main pipelines:
1. Data Injection Pipeline
This step prepares your data for retrieval.
Key Steps:
- Data Collection
- PDFs, CSVs, databases, APIs
- Parsing
- Convert raw data into structured format
- Chunking
- Break large documents into smaller pieces
- Embeddings
- Convert text into numerical vectors
- Vector Database
- Store embeddings for fast retrieval
2. Retrieval Pipeline
This step handles user queries.
Flow:
- User asks a question
- Query is converted into embeddings
- Vector DB performs similarity search
- Relevant context is retrieved
- Context + prompt → sent to LLM
- LLM generates accurate response
This process ensures responses are context-aware and grounded in real data
Key Components of a RAG System
LLM (Large Language Model)
- Generates final responses
Vector Database
- Stores embeddings
- Enables fast similarity search
Embedding Models
- Convert text into vectors
Document Processing
- Parsing, chunking, and structuring data
What is Chunking & Why It Matters?
Chunking is the process of splitting large documents into smaller parts.
Why it’s important:
- Fits within LLM context limits
- Improves retrieval accuracy
- Enhances performance
Without chunking, your system may fail or return poor results.
What is a Vector Database?
A vector database stores numerical representations of text (embeddings).
It allows:
- Semantic search
- Similarity matching
- Fast retrieval
Popular options include:
- ChromaDB
- FAISS
- Pinecone
Advantages of RAG
- Reduces hallucinations
- Provides real-time data access
- Works with private/internal data
- No need for costly fine-tuning
- Scalable and flexible
Real-World Use Cases
RAG is used in:
- AI Chatbots (customer support)
- Business intelligence systems
- Document search engines
- Knowledge assistants
- Research tools
As mentioned in the source, 90% of modern AI use cases involve RAG
Traditional LLM vs RAG
| Feature | Traditional LLM | RAG |
|---|---|---|
| Real-time data | No | Yes |
| Accuracy | Medium | High |
| Hallucination | High | Reduced |
| Private data usage | No | Yes |
| Cost | High (fine-tuning) | Low |
Future of RAG
RAG is evolving rapidly into:
- Agentic RAG (AI agents + retrieval)
- Context-aware systems
- Multi-modal RAG (text + images + video)
It’s becoming the foundation for next-gen AI applications.
Final Thoughts
RAG is not just a technique – it’s a fundamental shift in how AI systems are built.
Instead of relying only on pre-trained knowledge, we now build systems that:
- Retrieve
- Understand
- Generate
If you’re building AI products today, RAG is a must-have skill.
What’s Next?
In upcoming guides, we’ll cover:
- Hands-on RAG implementation
- Chunking strategies
- Embedding models comparison
- Vector database setup
💬 Have questions about RAG or building AI systems?
Drop a comment or reach out – happy to help!